In order to achieve reliability with commodity hardware, one has to resort to a replication scheme, where multiple redundant copies of data are stored. In normal operations, the cluster needs to write and replicate incoming data as quickly as possible, provide consistent reads and ensure metadata and services information are also redundantly maintained. When crashes occur, the customer is exposed to data loss until the replica is recovered and re-synchronized.
Production success with Hadoop requires a platform that not only stores data as system of record and ensures applications run 24×7, but also a platform that allows for easy integration with the rest of the enterprise data architecture and tools. MapR is the only distribution to provide these capabilities out-of-the-box and its architecture is key to how it achieves it.
Building a highly reliable, high performance cluster using commodity servers takes massive engineering effort. Data as well as the services running on the cluster must be made highly available and fully protected from node failures without affecting the overall performance of the cluster. Achieving such speed and reliability on commodity servers is even more challenging because of lack of non-volatile RAM or any specialized connectivity between nodes to deploy redundant data paths or RAID configurations.
This section describes the the various components of Hadoop: parts of the MapReduce job process, the handling of the data, and the architecture of the file system. As the book Hadoop In Action by Chuck Lam [page 22] says “Hadoop employs a master/slave architecture for both distributed storage and distributed computation”. In the distributed storage, the NameNode is the master and the DataNodes are the slaves. In the distributed computation, the Jobtracker is the master and the Tasktrackers are the slaves which are explained in the following sections.
MapReduce Job Processing: An entire Hadoop execution of a client request is called a job. Users can submit job requests to the Hadoop framework, and the framework processes the jobs. Before the framework can process a job, the user must specify the following:
- The location of the input and output files in the distributed file system
- The input and output formats
- The classes containing the map and reduce functions
Hadoop has four entities involved in the processing of a job:
- The user, who submits the job and specifies the configuration.
- Hadoop architecture,The JobTracker, a program which coordinates and manages the jobs. It accepts job submissions from users, provides job monitoring and control, and manages the distribution of tasks in a job to the TaskTracker nodes. Usually there is one JobTracker per cluster.
- The TaskTrackers manage the tasks in the process, such as the map task, the reduce task, etc. There can be one or more TaskTracker processes per node in a cluster.
- The distributed file system, such as HDFS.
The following figure from Pro Hadoop by Jason Venner [page 28] shows the different tasks of a MapReduce job.
 |
| Parts of a MapReduce job |
The user specifies the job configuration by setting different parameters specific to the job. The user also specifies the number of reducer tasks and the reduce function. The user also has to specify the format of the input, and the locations of the input. The Hadoop framework uses this information to split of the input into several pieces. Each input piece is fed into a user-defined map function. The map tasks process the input data and emit intermediate data. The output of the map phase is sorted and a default or custom partitioning may be applied on the intermediate data. Accordingly, the reduce function processes the data in each partition and merges the intermediate values or performs a user-specified function. The user is expected to specify the types of the output key and the output value of the map and reduce functions. The output of the reduce function is collected to the output files on the disk by the Hadoop framework.
Given below is the architecture of a Hadoop File System.
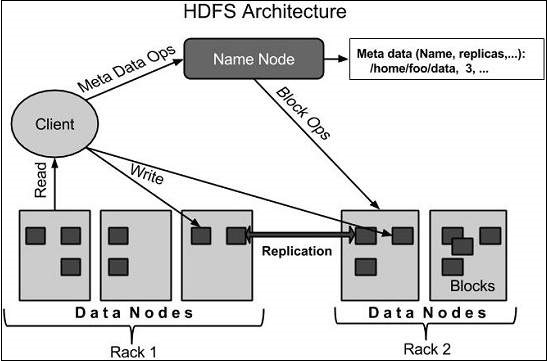
HDFS follows the master-slave architecture and it has the following elements.
Namenode: The namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software. It is a software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks:
- Manages the file system namespace.
- Regulates client’s access to files.
- It also executes file system operations such as renaming, closing, and opening files and directories.
Datanode: The datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node (Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their system.
- Datanodes perform read-write operations on the file systems, as per client request.
- They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode.
Block: Generally the user data is stored in the files of HDFS. The file in a file system will be divided into one or more segments and/or stored in individual data nodes. These file segments are called as blocks. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration.
Goals of HDFS:
- Fault detection and recovery : Since HDFS includes a large number of commodity hardware, failure of components is frequent. Therefore HDFS should have mechanisms for quick and automatic fault detection and recovery.
- Huge datasets : HDFS should have hundreds of nodes per cluster to manage the applications having huge datasets.
- Hardware at data : A requested task can be done efficiently, when the computation takes place near the data. Especially where huge datasets are involved, it reduces the network traffic and increases the throughput.